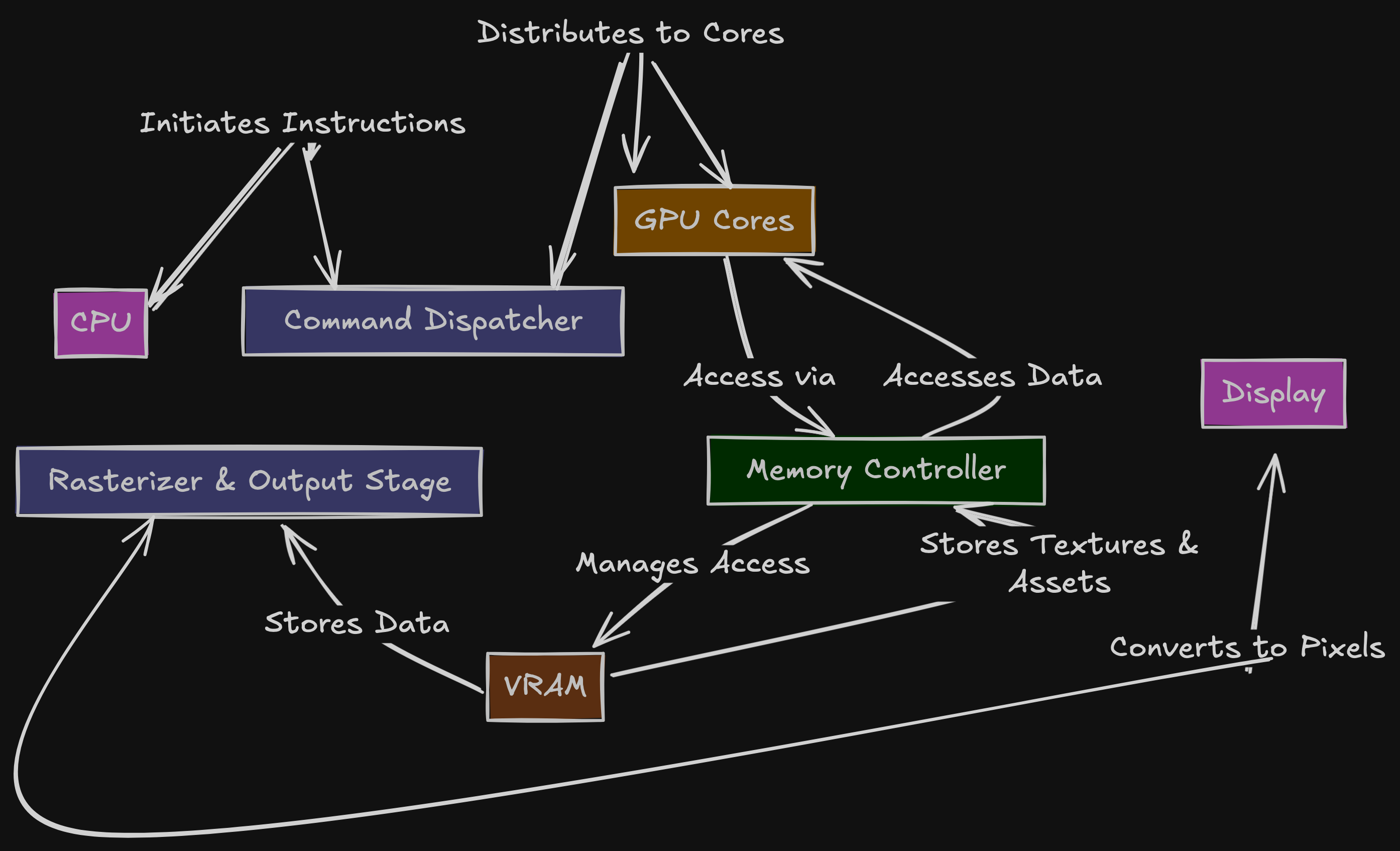
Machine Learning has evolved from small academic experiments to a global technology shaping search engines, autonomous vehicles, drug discovery, and personalized recommendations. But this evolution didn’t happen because algorithms alone improved—it happened because hardware evolved.
At the heart of this transformation lies GPU computing, the silent engine powering deep learning’s explosive growth. This article explores why GPUs became essential, how they work at a conceptual level, and where they outperform CPUs in modern ML workloads.
1. Why ML Outgrew CPUs
A CPU (Central Processing Unit) is built for serial workloads—processing a few complex tasks at high speed. It is the 'brain' of the computer, designed to be smart. It utilizes sophisticated control logic, such as branch prediction (guessing which path a program will take) and out-of-order execution, to minimize latency.
However, this 'smart' architecture comes at a cost: silicon area. A significant portion of a CPU die is dedicated to caching and control logic, leaving less room for the actual arithmetic logic units (ALUs) that do the math.
Machine learning, especially deep learning, is different. It doesn't involve complex branching logic. Instead, it relies on massive, repetitive mathematical operations:
- Matrix multiplication
- Convolution
- Vector addition
- Gradient computation
These operations involve applying the same mathematical operation over millions—even billions—of numbers. This is where CPUs struggle: they typically have 4–16 powerful cores, but that isn't enough for the massive parallelism required by modern AI.
2. The GPU Advantage: Parallelism at Scale
A GPU (Graphics Processing Unit) takes a completely different approach. Instead of a few powerful cores, it has thousands of smaller, simpler cores designed to handle many identical operations at the same time.
The Analogy: Imagine you need to transport 1,000 people.
- A CPU is like a Ferrari. It can transport 2 people extremely fast. But to move 1,000 people, it has to make 500 trips.
- A GPU is like a Bus. It moves slower than the Ferrari, but it can transport 50 people at once. It only needs 20 trips to move everyone.
Deep learning is a 'throughput' problem, not a 'latency' problem. We don't care how fast one individual neuron is calculated; we care how fast the entire network is processed.
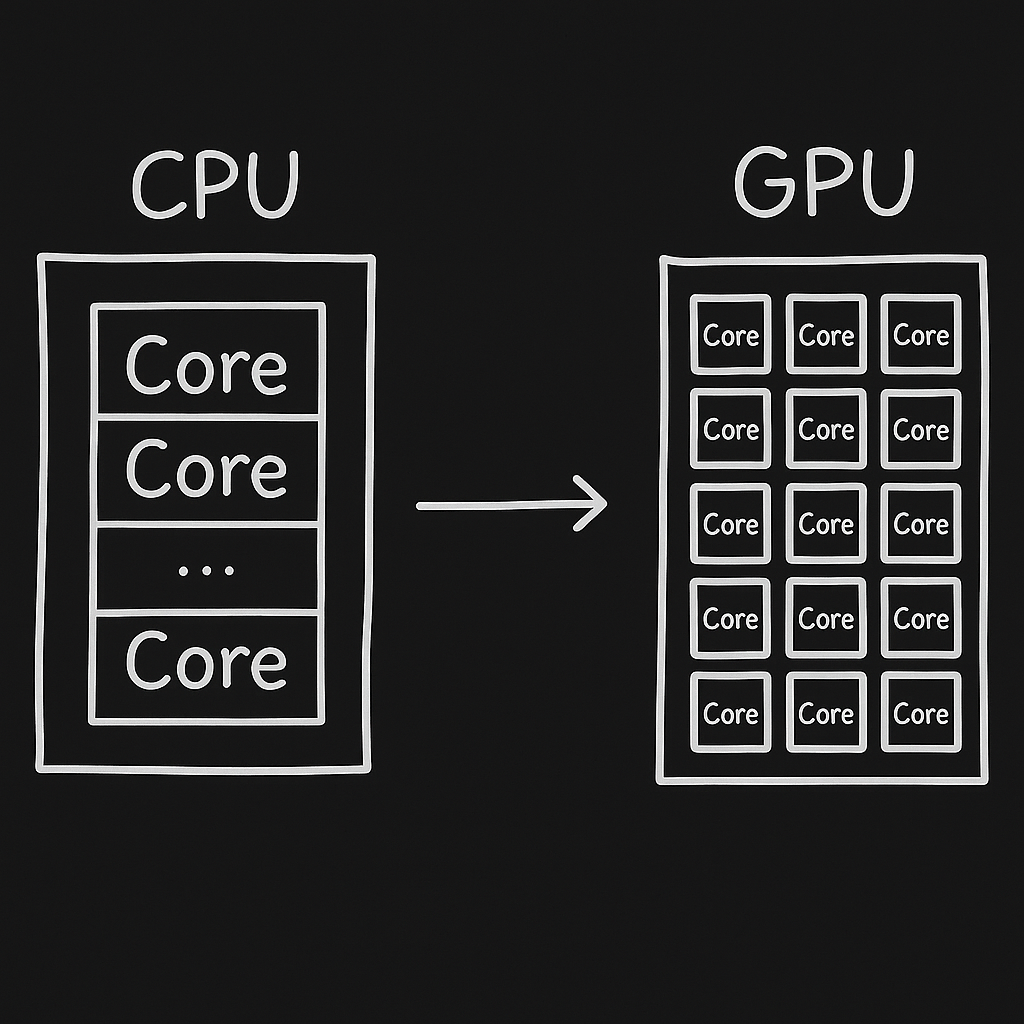
| Hardware | Core Type | Core Count | Best For |
|---|---|---|---|
| CPU | Heavyweight (Complex Control) | 4–64 | Sequential logic, OS, Latency-sensitive apps |
| GPU | Lightweight (Math Focused) | 1,000–18,000 | Parallel math, Graphics, AI |
3. Why ML Loves Matrix Multiplication
Deep learning is basically repeated matrix multiplication. For example, in a neural network layer: y = Wx + b. If W is 4096 × 4096 and x is 4096 × 1, that’s over 16 million multiplications in one forward pass.
This workload is embarrassingly parallel. The value of one output neuron does not depend on the value of its neighbor. This means a GPU can calculate thousands of these output values simultaneously, saturating its thousands of cores.
4. Parallelism in Practice: CPU vs GPU Example
Let's demonstrate matrix multiplication speed in NumPy (CPU) vs PyTorch (GPU). We will multiply two 4000x4000 matrices.
CPU (NumPy)
import numpy as np
import time
N = 4000
A = np.random.randn(N, N)
B = np.random.randn(N, N)
start = time.time()
C = A @ B
end = time.time()
print("CPU time:", end - start, "seconds")GPU (PyTorch + CUDA)
import torch
import time
device = "cuda"
N = 4000
A = torch.randn(N, N, device=device)
B = torch.randn(N, N, device=device)
# We synchronize to ensure we measure the actual computation time
torch.cuda.synchronize()
start = time.time()
C = A @ B
torch.cuda.synchronize()
end = time.time()
print("GPU time:", end - start, "seconds")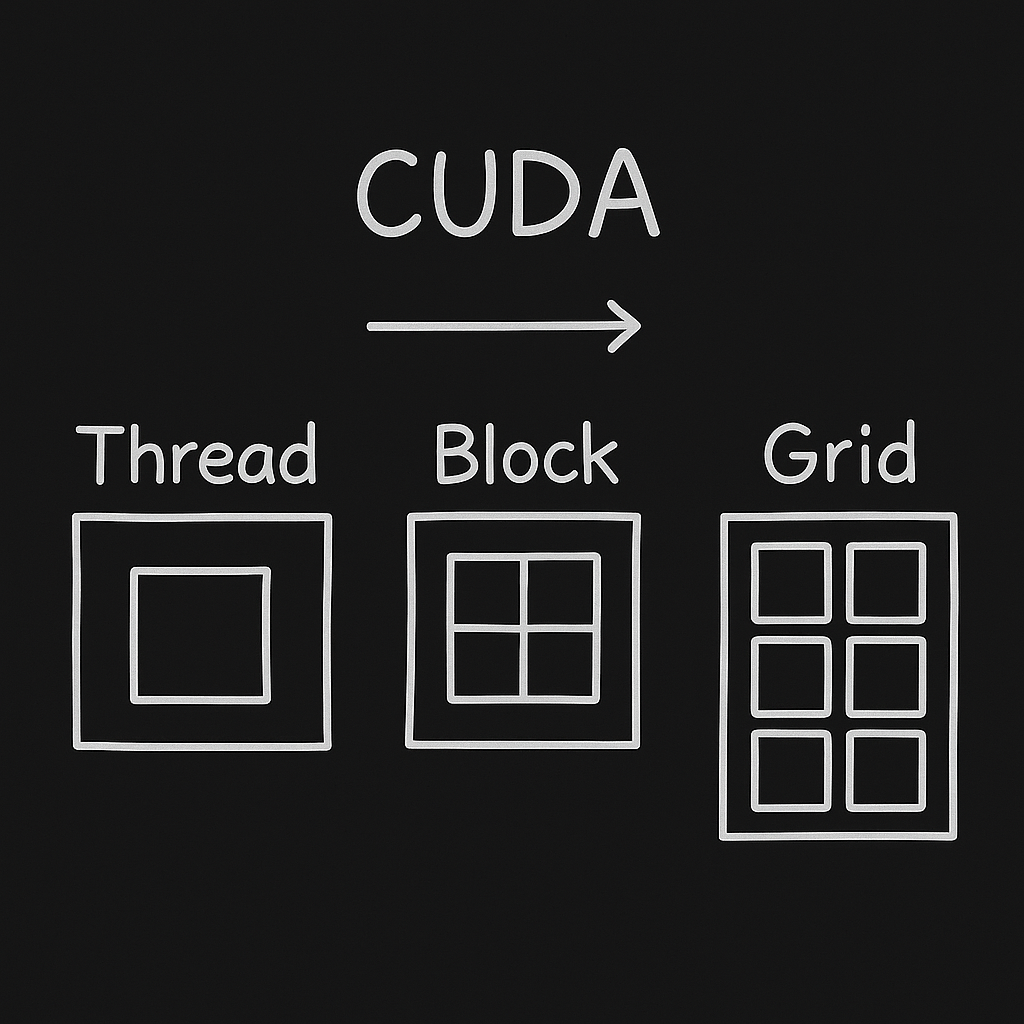
Typical output on consumer hardware:
- CPU: ~2–6 seconds
- GPU: ~0.02–0.06 seconds
That is a 100× speedup. This difference changes the workflow from 'wait over the weekend' to 'wait for a coffee break'.
5. Inside a GPU: SIMD + SIMT Computing
How does the GPU manage thousands of threads without getting bogged down? It uses execution models designed for uniformity:
- SIMD (Single Instruction, Multiple Data): One instruction (e.g., 'add') is applied across many data elements simultaneously.
- SIMT (Single Instruction, Multiple Threads): NVIDIA's extension of SIMD. Threads run in parallel groups (called 'warps') but have the flexibility to diverge if absolutely necessary (though divergence hurts performance).
Deep learning frameworks (PyTorch/TensorFlow) compile your Python code into kernels—small programs that run on the GPU. These kernels map your matrix operations into the SIMT architecture, ensuring that every core is kept busy.
6. Memory Bandwidth: The Hidden Hero
It’s not just about raw compute power. A processor is only as fast as the data you can feed it. This is known as the Memory Wall.
Deep learning models are massive. GPT-3 has 175 billion parameters. Moving these weights from memory to the compute cores is often the bottleneck. GPUs solve this with HBM (High Bandwidth Memory) and wide memory buses.
| Hardware | Typical Bandwidth |
|---|---|
| CPU (DDR4/DDR5) | 30–60 GB/s |
| GPU (RTX 4090 - GDDR6X) | 1,008 GB/s |
| GPU (A100 - HBM2e) | 2,000+ GB/s |
An A100 GPU has over 30x the memory bandwidth of a standard CPU. This allows it to chew through massive datasets without starving for data.
7. Real-world ML Workloads that NEED GPUs
- Deep Neural Networks (CNNs/Transformers): These are the backbone of modern AI, used in everything from ChatGPT to self-driving cars. They require billions of matrix ops.
- Large-Scale Training: Training a model like Llama 3 requires thousands of GPUs working in concert for months.
- Generative AI: Creating an image with Stable Diffusion involves iterative 'denoising' steps, each requiring a full pass through a massive U-Net.
- Scientific Simulation: Protein folding (AlphaFold) and weather prediction use the same matrix math as AI, making GPUs ideal for science.
Conclusion: The Parallel Revolution
Modern machine learning is powered not just by clever algorithms, but by a revolution in parallel computing. GPUs provided the hardware lottery ticket that allowed neural networks—a concept from the 1950s—to finally scale.
In short: Machine Learning needed GPUs not just to grow—but to exist in its modern form.